PSHuman Learning
PSHuman Learning
1 前置知识
2 核心过程
2.1 基于SMPL-X先验条件的跨尺度多视角扩散生成
这一阶段的目标是根据输入的单张图像,生成高质量、多视角(6个视图:前、左前、左、后、右、右前)的彩色图和法线图,同时要确保一致性。
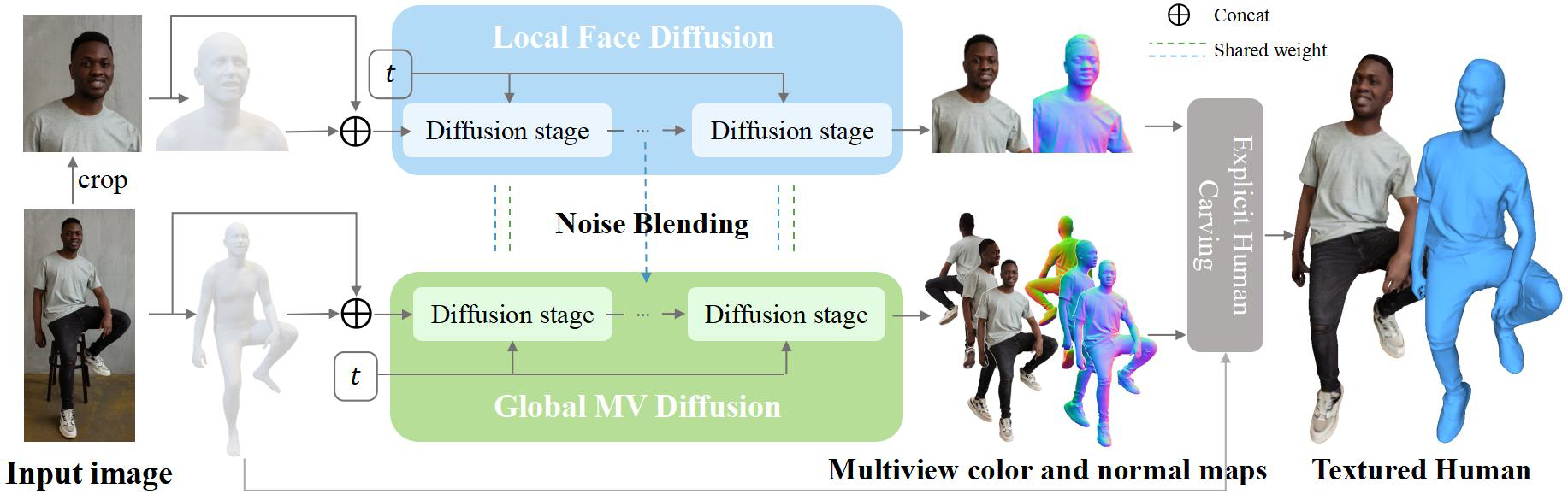
2.1.1 条件扩散模型
采用U-Net结构地神经网络作为去噪网络。U-Net地编码器-编码器结构及其跳跃连接非常适合图像到图像地转换任务,能够捕捉不同尺度地特征,生成多视角图像。
训练
- 数据准备:3d人体模型数据对。对于每个3d人体模型,从多个预设视点渲染其彩色图和法线图。
- 前向扩散:对训练集中地多视角图像进行逐步加噪过程,得到不同时间步t地噪声版本\(x_t\)。
- 反向去噪:训练去噪网络\(\epsilon(x_t, t, cond)\)来预测在时间t添加到\(x_{t-1}\)上的噪声\(\epsilon\),其中condi是条件信息。
条件注入
条件注入是引导扩散模型生成特定内容的关键,PSHuman中条件cond主要包括:
1. 输入图像\(I_{in}\):全局信息,通过预训练的图像编码器提取特征。
2. 目标视点\(v_i\):指定模型当前要生成的视图的角度,是一个类别标签(例如“左视图”)。
3. SMPL-X先验:1)估计:首先,从输入图像\(I_{in}\)中使用已有的SMPL-X参数估计算法(如PIXIE,SPIN,CLIFF等)得到姿态参数\(\theta_{smplx}\)和形状参数\(\beta_{smplx}\)。2)渲染:使用这些参数渲染出该SMPL-X模型在目标视点\(v_i\)下的图像。3)编码与注入:将上面生成的SMPL-X渲染图编码(使用Variational
Autoencoder)为特征,并与输入图像特征、视点信息一起注入到U-Net的各个层级。
SMPL-X先验极大地缓解了单视图地歧义性,为扩散模型提供了关于人体结构、比例和当前姿态的强约束,有助于生成被遮挡区域和保持跨视图的一致性。
论文中的表述为:The introduction of these conditional signals constrains the multiview distribution, leading to more accurate and consistent human image generation. This approach significantly enhances the model’s generalization capability on complex human poses with self-occlusion.
2.1.2 跨尺度身体-面部扩散
全身图像中,面部区域像素占比较小,直接用全局模型生成难以保证面部细节和身份特征,容易造成面部失真,人类对于面部改变非常敏感,所以这通常是不可接受的。
所以将面部信息和全局信息解耦,分别使用单独的扩散模型生成对应图像,并最后想办法将两者结合:
- 全局分支:一个扩散模型负责生成整个身体在多个视角的图像。
-
局部(面部)分支:另一个扩散模型利用裁剪出的面图区域专门负责生成高分辨率的面部图像。
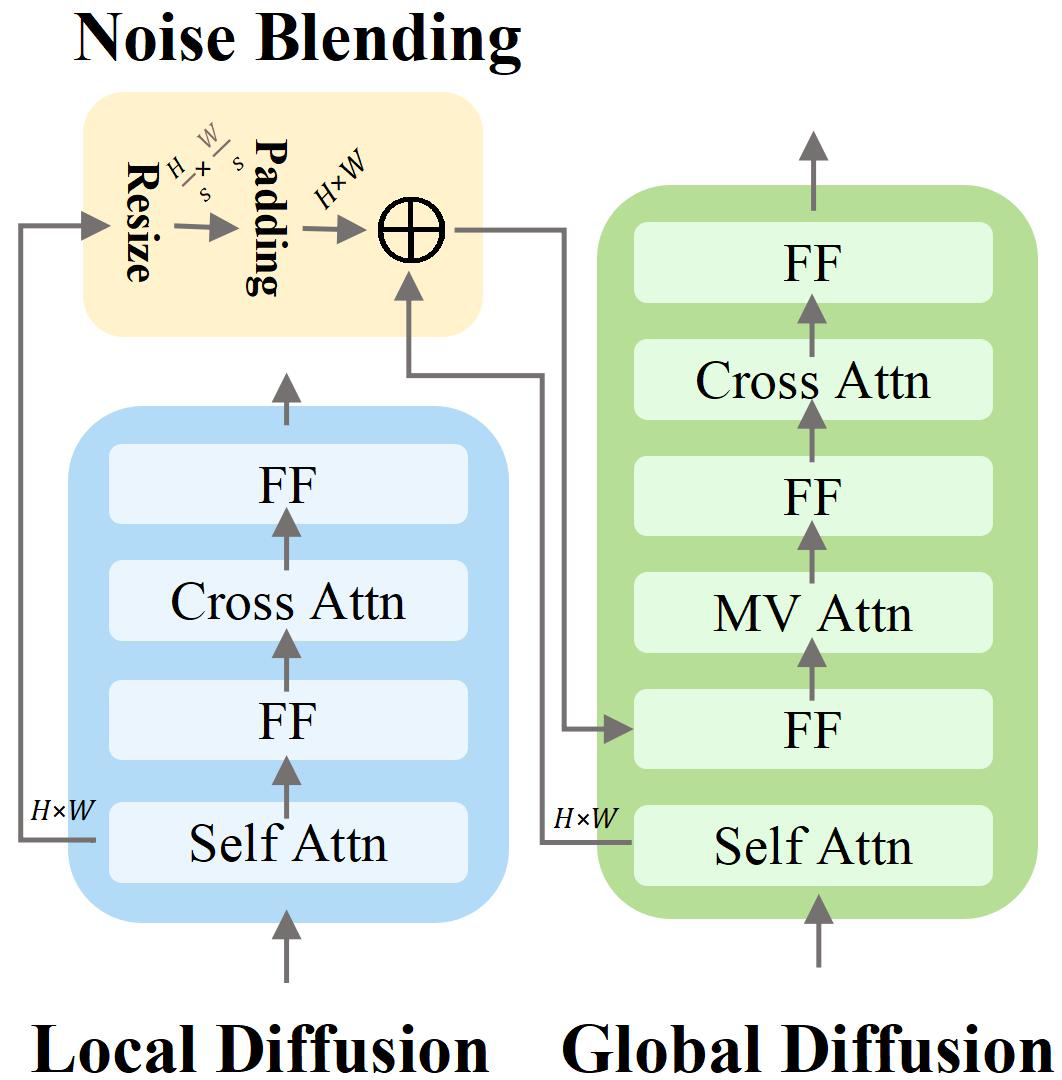
之后通过噪声混合层结合上面两个分支的信息,在扩散模型的去噪过程中间步骤进行交互:
1.
在全局分支的UNet中,当处理到某个包含面部区域的特征图时,提取同一时间步t和对于网络深度处局部分支UNet生成的面部潜向量\(h_F\)。
2. 将\(h_F\)进行适当的缩放和填充(RP函数),使其尺寸与全局分支特征图中面部区域的尺寸对齐。
3. 使用一个二值掩码\(w\)来定位全局分支特征图中的面部区域。
4. 将处理后的\(h_F\)乘以权重\(w\)并加权求和到全局分支的面部特征区域特征\(h_B\)上:\(h_B =
h_B + w \cdot RP(h_F, s)\)
这样,局部分支专注于面部,可以生成更精细的集合和纹理,专门处理面部能够更好地保留输入图像中地身份特征。而在特征层面进行融合,而不是图像层面地简单拼接,保证了面部与身体其他部分的平滑过渡和光照、风格的一致性,噪声的混合确保了面部信息能够影响到后续全局视图的生成。
当所有去噪步骤完成后,两个分支分别输出结果:1)全局分支输出6个视角的全身彩色图\(c_i^{body}\)和法线图\(N_i^{body}\)。2)局部分支输出高分辨率的面部彩色图\(c^{face}\)和法线图\(N^{face}\)。最终的正面视图的彩色图和法线图以面部分支的结果为主,而其他非正面视图的面部则依赖全局分支通过跨试图注意力从正面传递信息。
2.2 SMPL-X初始的显式人体雕刻
这一阶段主要利用上面生成的多视角彩色图\(C_i\)和法线图\(N_i\),重建出最终带纹理的3D三角网格M。
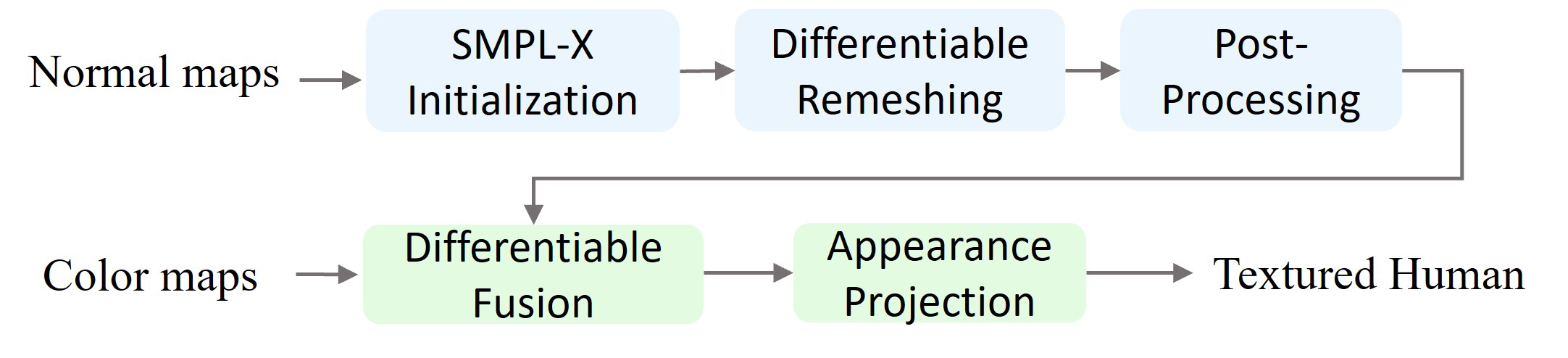
2.2.1 基于SMPL-X的先验网格
使用上面从输入图像\(I_in\)估计得到的SMPL-X参数\((\theta_{smplx, \beta_{smplx}})\)生成初始的3D人体网格\(M_{init}\)。在上一阶段生成的多视角图像可能与标准的SMPL-X模型存在轻微的未对齐,所以在正式雕刻前进行对齐,即优化SMPL-X模型的平移t、形状\(\beta\)和姿态\(\theta\)参数,使得渲染出的多视角法线图\(N_i^{hat}\)和轮廓图\(S_i^{hat}\)与上阶段生成的法线图\(N_i\)和从\(N_i\)推断的轮廓图\(S_i\)之间的差异最小,即\(t, \beta, \theta = \mathop{\arg \min}\limits_{t, \beta, \theta} \sum w_i(||N_i - N_i^{hat}||_2 + ||S_i - S_i^{hat}||_2)\)。
2.2.2 基于可微光栅化的几何重网格化
在\(M_{init}\)对齐后\(M_{current}\)的基础上,进一步雕刻出衣物褶皱、肌肉形态等精细几何细节。
迭代优化过程:
1. 从每个视点\(v_i\),使用可微光栅化器渲染\(M_{current}\)的法线图\(N_i^{hat}(M_{current})\)和轮廓图\(S_i^{hat}(M_{current})\)。
2. 计算渲染结果与上一阶段生成的目标法线图\(N_i\)和轮廓图\(S_i\)之间的L2损失:\(Loss_{geo} = \sum {w_i(||N_i -
N_i^{hat}(m_{current})||_2 + ||S_i -
S_i^{hat}(M_{current})||_2)}\)。
3.
为了保持网格的平滑性,防止出现不自然的表明,通常会加入一个正则化项,例如顶点发现与其邻近顶点平均发现之间差异的惩罚:\(Loss_{reg} = \lambda \sum (n_j -
n_j^{neig})\),其中\(n_j\)是顶点法线,\(n_j^{neig}\)是邻居法线,\(\lambda\)是权重。
4. 总损失\(Loss_{total} = Loss_{geo} +
Loss_{reg}\)。
5. 计算\(Loss_{total}\)相对于\(M_{current}\)顶点位置\(V\)的梯度,根据梯度更新顶点位置\(V\)。
6. 重复上述步骤,直到收敛或达到预设的迭代次数。
另外在网格优化后,可能存在一些未闭合区域,使用泊松表面重建算法来平滑地填补这些区域;手部细节通常很难完美重建,所以可以使用估计的SMPL-X手部模型替换掉雕刻后的手部。
2.2.3 外观融合与纹理化
进一步,为优化好的几何网络\(M_{optimized}\)赋予纹理。
对每个顶点的颜色,其VC迭代优化过程:
1. 对于每个顶点\(v_i\),使用可微光栅化器渲染\(M_{optimized}\)得到彩色图像\(C_i^{hat}(M_{optimized},
VC_{current})\)。
2. 计算渲染的彩色图像与2.1生成的目标彩色图像\(C_i\)之间的L2损失:\(Loss_{appearance} = \sum w_i ||C_i -
C_i^{hat}(M_{optimized}, VC_{current})||_2\)。
3. 计算\(Loss_{appearance}\)相对于\(VC_{current}\)的梯度,根据梯度更新顶点颜色VC。
4. 重复上述步骤,直到收敛或达到预设的迭代次数。
对于从所有六个视图都不可见的区域,它们的颜色信息不能直接从\(C_i\)中获得,此时利用已确定颜色的可见邻近顶点信息,通过基于KDTree的插值方法,沿表面进行插值,为不可见区域赋予合理的颜色,以确保纹理的完整性和视觉上的连续性。
原文的表述为:In the majority of cases, this color fusion pipeline suffices to generate high-quality appearances. However, certain areas may remain unobserved from the predefined six viewpoints. Thus, we finally compute a visibility mask and perform topology-aware interpolation based on KDTree, ensuring comprehensive texture coverage.